Binary Ninja Binary Lifting Plugin - [Z80 Lifting]
Plugin 작성
- Plugins → Open Plugin Folder… 를 클릭하여 plugin 폴더 진입
- plugin 폴더에
hello.py생성
hello.py내용
1
print("Hello World!")
이후 Binary Ninja를 다시 실행하면 로그창에 Hello World! 문자열이 출력된 것을 볼 수 있음.
Binary Ninja의 API를 사용하면 다음과 같이 작성할 수 있음.
1
2
from binaryninja.log import log_info
log_info("Hello, World!")
이 시점부터 코드는 Binary Ninja에게 플러그인 명령어, 바이너리 뷰, 또는 완전히 새로운 아키텍처임을 선언할 수 있다.
Architecture 추가
Architecture클래스를 상속받아 새로운 아키텍처를 만들 수 있다.- 새로운 Architecture 이름을
Z80이라고 명명 - class 이름을
Z80으로 작성 name변수는 아키텍처 이름이 저장되는 변수이다 :‘Z80’문자열 저장
- 새로운 Architecture 이름을
Z80.register()를 통해 새로운 Architecture를 등록한다.
1
2
3
4
5
6
from binaryninja.architecture import Architecture
class Z80(Architecture):
name = 'Z80'
Z80.register()
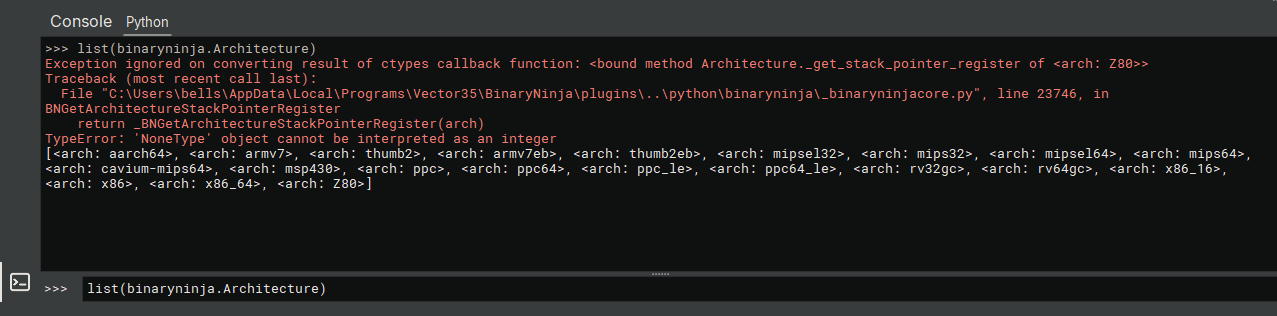
- Console 버튼을 클릭하면 Python 콘솔 뷰가 생김

- 콘솔 뷰에
list(binaryninja.Architecture)를 입력하면Z80이라는 Architecture가 등록된 것을 볼 수 있음.
Architecture 이름을 저장하는 name 변수 외에도 여러 변수를 설정하여 Binary Ninja에 전달할 수 있다.
1
2
3
4
5
6
7
8
9
10
from binaryninja.architecture import Architecture
class Z80(Architecture):
name = 'Z80'
address_size = 2 # 16-bit addresses
default_int_size = 1 # 1-byte integer
instr_alignment = 1 # no instruction alignment
max_instr_length = 3 # maximum length
Z80.register()
Register 정의
레지스터 이름이 key 이고 RegisterInfo 객체가 value인 사전을 작성함으로써 레지스터 정의가 가능하다.
1
2
3
4
5
6
7
8
class Z80(Architecture):
...
regs = {
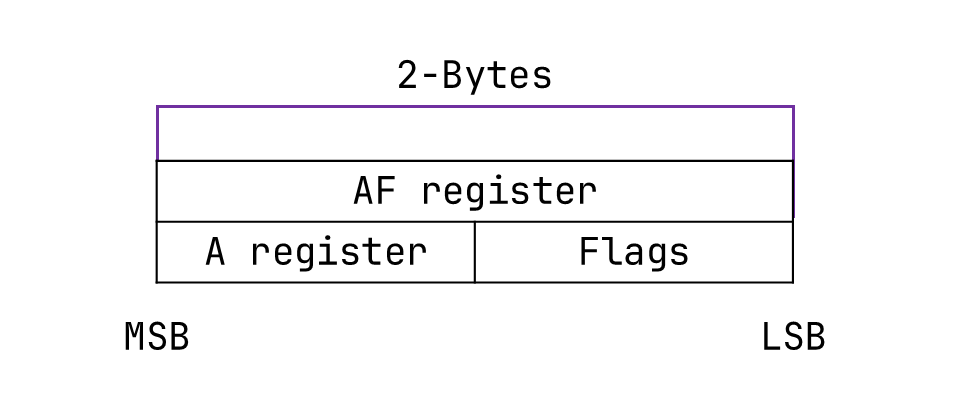
'AF': RegisterInfo('AF', 2),
'A': RegisterInfo('AF', 1, 1), # sub-register of 'AF', 1-byte, offset 1
'Flags': RegisterInfo('AF', 0), # sub-register of 'AF', 1-byte, offset 0
}
'AF': RegisterInfo('AF', 2):- AF 레지스터는 AF 레지스터의 하위 레지스터이며 크기가 2이다.
- 즉, 하위 레지스터와의 관계가 자신을 가리키기 때문에 Binary Ninja는 이 레지스터가 전체 너비 레지스터라는 것을 인지한다.
- 반면에
A레지스터의 경우는:A레지스터는AF레지스터의 하위 레지스터이고, 크기가 1이며,AF레지스터의 LSB에서 바이트 오프셋 1에 있다 라는 뜻이다.
Flags레지스터의 경우는:Flags레지스터는AF레지스터의 하위 레지스터이고, 크기가 1이며,AF레지스터의 LSB에서 바이트 오프셋 0에 있다 라는 뜻이다.
Stack Pointer 레지스터 설정
Stack Pointer 또는 Link Register의 역할을 하는 레지스터가 있다면 이를 설정해야 한다.
1
stack_pointer = "SP"
Disassemble
Disassemble 하기 위해서는 콜백 함수를 구현해야 한다. Architecture에서 사용할 수 있는 콜백 기능은 많지만, 필요한 것은 세 가지뿐이다.
get_instruction_info(): Binary Ninja가 control-flow 그래프를 그리는 데 도움을 주는 함수get_instruction_text(): 바이트를 disassemble 하는 함수get_instruction_low_level_il(): binary lifting 위한 함수
get_instruction_info() 함수는 InstructionInfo() 를 반환하여, instruction의 길이와 branch behavior(분기 동작)을 설명한다.
1
2
3
4
5
def get_instruction_info(self, data, addr):
result = InstructionInfo()
result.length = 1
return result
get_instruction_text() 함수는 InstructionTextToken 목록과 instruction 크기를 반환하여 사용자에게 제시된 실제 텍스트를 설명한다.
1
2
3
4
def get_instruction_text(self, data, addr):
tokens = [InstructionTextToken(InstructionTextTokenType.TextToken, "HELLO!")]
return tokens, 1
get_instruction_low_level_il() 함수는 일단 None 을 반환하게 작성한다.
1
2
def get_instruction_low_level_il(self, data, addr, il):
return None
- New File 클릭
- hex view 에 내용 작성
aaaaaaa...

- Make Function at This Address → Z80 → Z80 선택
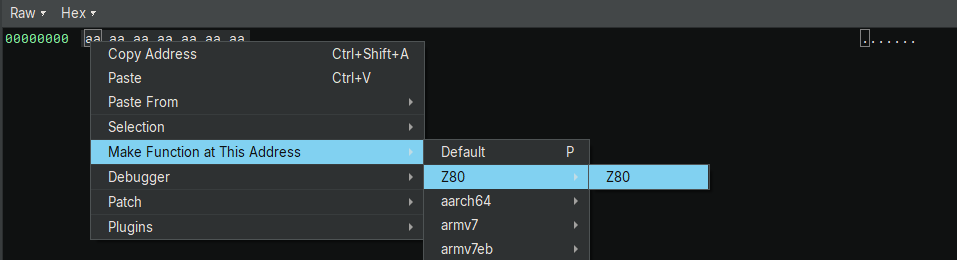
- Z80 Architecture 에 대한 함수가 만들어 진다.
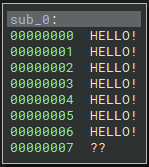
본격적인 Disassemble 작업을 위해서 기존에 만들어진 z80 Disassembler를 사용할 예정이다.
z80dis패키지 설치- Ctrl + p 를 눌러 Command Palette View 띄우기
Install python3 module을 클릭
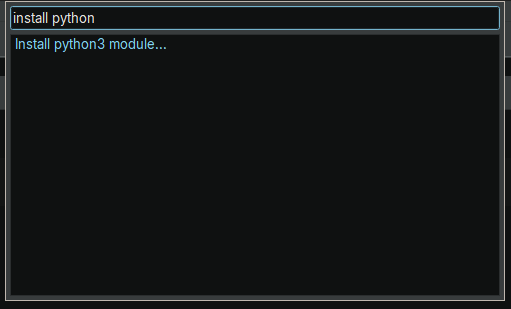
z80dis패키지 입력
먼저 get_instruction_info() 에 올바른 크기를 반환하도록 작성한다.
1
2
3
4
5
6
7
8
9
def get_instruction_info(self, data, addr):
decoded = z80.decode(data, addr)
if instrLen == 0:
return None
result = InstructionInfo()
result.length = decoded.len
return result
다음에 get_instruction_text() 에 올바른 문자열을 반환하도록 작성한다.
1
2
3
4
5
6
7
def get_instruction_text(self, data, addr):
instrTxt = z80.disasm(data, addr)
decoded = z80.decode(data, addr)
tokens = [InstructionTextToken(InstructionTextTokenType.TextToken, instrTxt)]
return tokens, decoded.len
테스트를 위해 다음과 같이 작성한다.
1
binaryninja.Architecture['Z80'].get_instruction_text(b'\x2a\x34\xbc\x1a', 0)
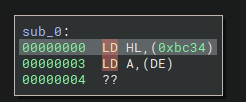
정상적으로 명령어 코드가 나오는 것을 볼 수 있다.

LD HL, (0xbc34) 를 분해하면 다음과 같다.
| token | type |
|---|---|
| LD | InstructionToken: instruction 니모닉 |
| HL | RegisterToken: 레지스터 |
| , | OperandSeparatorToken: 기타 토큰 분리 |
| ( | BeginMemoryOperand |
| 0xbc34 | PossibleAddressToken: 주소일 가능성이 높은 헥스 |
| ) | EndMemoryOperandToken: 메모리 피연산자 |
토큰을 분해 후 바이너리 닌자 UI에 Token의 타입을 지정하여 보여줄 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
result = []
atoms = [t for t in re.split(r'([, ()\+])', instrTxt) if t]
result.append(InstructionTextToken(InstructionTextTokenType.InstructionToken, atoms[0]))
if atoms[1:]:
result.append(InstructionTextToken(InstructionTextTokenType.TextToken, ' '))
for atom in atoms[1:]:
if not atom or atom == ' ':
continue
# PROBLEM: cond 'C' conflicts with register C
# eg: "RET C" is it "RET <reg>" or "REG <cc>" ?
# eg: "CALL C" is it "CALL <reg>" or "CALL C,$0000" ?
elif atom == 'C' and atoms[0] in ['CALL','RET']:
# flag, condition code
result.append(InstructionTextToken(InstructionTextTokenType.TextToken, atom))
elif atom in self.reg16_strs or atom in self.reg8_strs:
result.append(InstructionTextToken(InstructionTextTokenType.RegisterToken, atom))
elif atom in self.cond_strs:
result.append(InstructionTextToken(InstructionTextTokenType.TextToken, atom))
elif atom.startswith('0x'):
result.append(InstructionTextToken(InstructionTextTokenType.IntegerToken, atom, int(atom[2:],16)))
elif atom[0] == '$':
if len(atom)==5:
result.append(InstructionTextToken(InstructionTextTokenType.PossibleAddressToken, atom, int(atom[1:],16)))
else:
result.append(InstructionTextToken(InstructionTextTokenType.IntegerToken, atom, int(atom[1:],16)))
elif atom.isdigit():
result.append(InstructionTextToken(InstructionTextTokenType.IntegerToken, atom, int(atom)))
elif atom == '(':
result.append(InstructionTextToken(InstructionTextTokenType.BeginMemoryOperandToken, atom))
elif atom == ')':
result.append(InstructionTextToken(InstructionTextTokenType.EndMemoryOperandToken, atom))
elif atom == '+':
result.append(InstructionTextToken(InstructionTextTokenType.TextToken, atom))
elif atom == ',':
result.append(InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, atom))
else:
raise Exception('unfamiliar token: from instruction %s' % (instrTxt))
return result, instrLen
Branch Information
- UnconditionalBranch
- 기본 블럭 종료
- FunctionReturn
- 함수 종료
- TrueBranch, FalseBranch
- control flow 그래프를 참, 거짓에 따라 나누기 위한 블럭
- CallDestination
- Binary Ninja에 더 많은 코드를 분해하기 위해서 재귀적으로 어디를 찾아야 하는지 알려준다.
disassemble 시 반환된 문자열을 정규 표현식 통해 검증 후 어떤 것이 적용되는지에 따라 적절한 BranchType을 추가한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
rccs = r'(?:C|NC|Z|NZ|M|P|PE|PO)'
regexes = [ \
r'^(?:JP|JR) '+rccs+r',\$(.*)$', # 0: conditional jump eg: JP PE,#DEAD
r'^(?:JP|JR) \$(.*)$', # 1: unconditional jump eg: JP #DEAD
r'^(?:JP|JR) \((?:HL|IX|IY)\)$', # 2: unconditional indirect eg: JP (IX)
r'^DJNZ \$(.*)$', # 3: dec, jump if not zero eg: DJNZ #DEAD
r'^CALL '+rccs+r',\$(.*)$', # 4: conditional call eg: CALL PE,#DEAD
r'^CALL \$(.*)$', # 5: unconditional call eg: CALL #DEAD
r'^RET '+rccs+'$', # 6: conditional return
r'^(?:RET|RETN|RETI)$', # 7: return, return (nmi), return (interrupt)
]
m = None
for (i,regex) in enumerate(regexes):
m = re.match(regex, instrTxt)
if not m:
continue
if i==0 or i==3:
dest = int(m.group(1), 16)
result.add_branch(BranchType.TrueBranch, dest)
result.add_branch(BranchType.FalseBranch, addr + instrLen)
pass
elif i==1:
dest = int(m.group(1), 16)
result.add_branch(BranchType.UnconditionalBranch, dest)
pass
elif i==2:
result.add_branch(BranchType.IndirectBranch)
pass
elif i==4 or i==5:
dest = int(m.group(1), 16)
result.add_branch(BranchType.CallDestination, dest)
pass
elif i==6:
pass # conditional returns don't end block
elif i==7:
result.add_branch(BranchType.FunctionReturn)
break
Reference
- https://binary.ninja/2020/01/08/guide-to-architecture-plugins-part1.html
- https://dev-api.binary.ninja/